The last few years have seen increased interest in Machine Learning – Neural Networks (NN’s) in finance. Here I will focus specifically on the application of NN’s to function approximation, so basically derivatives pricing and consequently risk calculations. The goal is to either “turbo-boost” models/calculations that are already in production systems, or enable the use of alternative/better models that were previously not practical due to the high computational cost. I’ve been hearing claims of millions of times faster calculations and that the Universal Approximation Theorem guarantees that all functions can be approximated accurately by the simplest kind of net, provided enough training samples. But as usual the devil is in the details; like exactly how many training samples are we talking about to achieve a typical production system level of accuracy? I was wondering, what if to guarantee acceptable accuracy one would need impractically large training sets (and hence data generation and training times)? And never mind millions of times faster (perhaps more realistic for quantum computers when they arrive?), I would be satisfied with 100 or even 10 times faster, provided it was easy enough to implement and deploy.
There have been waves of renewed interest in NN's for decades, but their recent resurgence is in large part due to them been made more accessible via Python packages like TensorFlow and PyTorch that hide away the nitty gritty that would otherwise dishearten most of the recent users. So given the low barrier to entry and having been spurred on by a couple of people, I decided to check out this seemingly all-conquering method. Moreover, this seems like an engineering exercise; one needs to be willing to try a lot of different combinations of “hyperparameters”, use suitable training sample generation techniques and bring in experience/tricks from traditional methods, all with the aim to improve the end result. Not to mention "free" time and relatively cheap, sustainable electricity. That’s me then this year I thought.
I am not sure what is the state of adoption of such NN applications in finance right now. Looking at relevant papers, they all seem to be fairly recent and more the proof-of-concept type. What puzzles me in particular is the narrow input parameter range used to train the NN's on. Surely one would need more coverage than that in practice? Consequently there is talk that such (NN) models would need to be retrained from time to time when market parameters get out of the “pre-trained” range. Now I may be missing something here. First, I think it would be less confusing to call them "NN approximations" instead of "NN models" since they simply seek to reproduce the output of existing models. The application of NN’s in this context really produces a kind of look-up table to interpolate from. As for the limited range of parameters that is usually chosen for training in the relevant literature, I imagine it has to do with the fact that the resulting approximation's accuracy is of course higher like that. But this does not give me any assurance that the method would be suitable for real-world use, where one would need quite a bit higher accuracy still than what I have seen so far and also wider input ranges.
So I decided I want hard answers: can I approximate a model (function) in the whole (well almost) of its practically useful parameter space so that there’s no need to retrain it, like never (unless the original is changed of course)? To this aim I chose a volatility model calibration exercise as my first case study. Which is convenient because I had worked on this before. Note that a benefit of the NN approach (if it turns out they do the job well) is that one could make the calibration of any model super-fast, and thus enable such models as alternatives to the likes of Heston and SABR. The latter are popular exactly because they have fast analytical solutions or approximations that make calibration to market vanillas possible in practical timescales.
To demonstrate said benefit, the logical thing to do here would be to come up with a turbo-charged version of the non-affine model demo calibrator. The PDE method used in there to solve for vanilla prices under those models is highly optimized and could be used to generate the required millions of training samples for the NN in a reasonable amount of time. To keep things familiar though and save some time, I will just try this on the Heston model whose training samples can be generated a bit faster still (I used QLib’s implementation for this). If someone is interested in a high accuracy, production-quality robust calibration routine of any other volatility model, feel free to get in touch to discuss.
Like I said above, the trained parameter range is much wider than anything I’ve seen published so far but kind of arbitrary. I chose it to cover the wide moneyness (S/K) range represented by the 246 SPX option chain A from [1]. Time to maturity ranges from a few days up to 3 years. The model parameters should cover most markets. The network has about 750,000 trainable parameters, which may be too many, but one does not know beforehand what accuracy can be achieved with what architecture. It is possible that a smaller (and thus even faster) network can give acceptable results. 32 million optimally placed training samples were used. I favored accuracy over speed here, if anything to see just how accurate the NN approximation can practically get. But also because higher accuracy minimizes the chance of the optimizer converging to different locales (apparent local minima) depending on the starting parameter vector (see [3] for more on this).
Overall this is a vanilla calibration set-up, where a standard optimizer (Levenberg-Marquardt) is used to minimize the root mean square error between the market and model IV's, with the latter provided by the (Deep) NN approximation. There are other more specialized approaches involving NN's designed specifically for the calibration exercise, see for example the nice paper by Horvath et al. [4]. But I tried to keep things simple here. So how does it perform then?
| Neural Network Approximation specification | ||||
| Operational parameter ranges | ||||
| min | max | |||
| S/K | 0.5 | 5 | ||
| T | 0.015 | 3 | ||
| r | -0.02 | 0.1 | ||
| d | 0 | 0.1 | ||
| v0 | 0.002 | 0.5 | ||
| v̅ | 0.005 | 0.25 | ||
| κ | 1 | 20 | ||
| ξ | 0.1 | 10 | ||
| ρ | -0.95 | 0.1 | ||
| Performance | ||||
| Mean Absolute IV Error | 9.3×10-6 | |||
The mean absolute error is about 1.e−3 implied volatility percentage points (i.e. 0.1 implied volatility basis points).
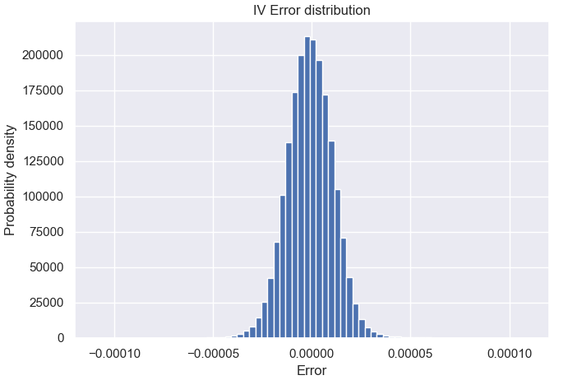
The maximum error over a test set of 2 million (out of sample) random points was 5 IV basis points but that is in an area of the parameter hypercube of no interest in practice. For example on the moneyness - expiration plane, the error distribution looks like this:
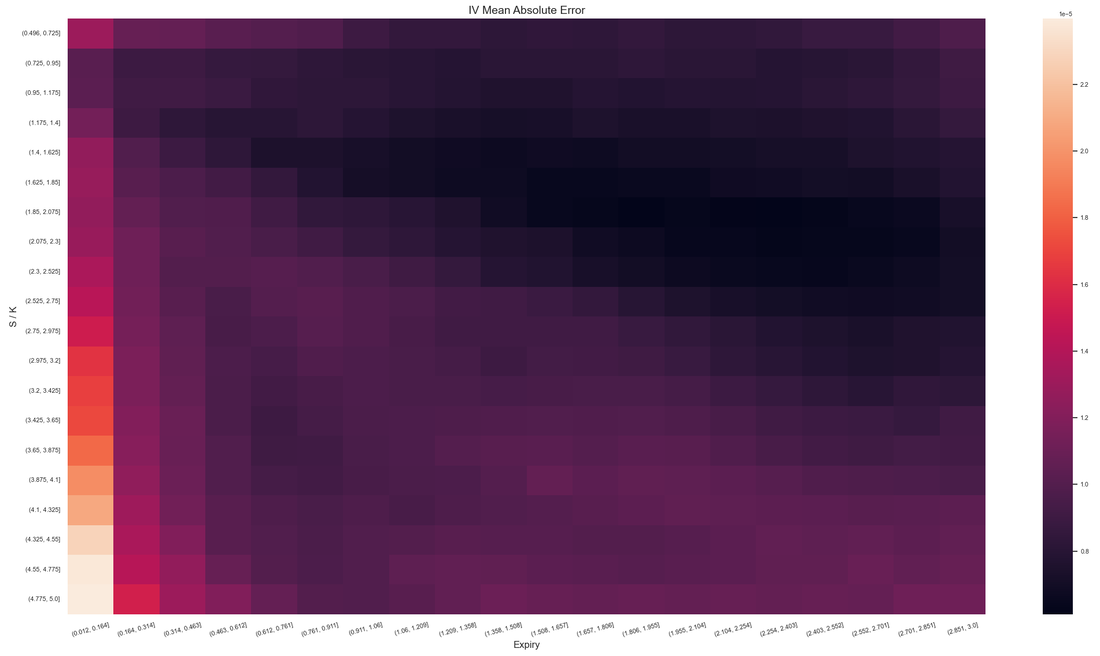
Obviously for individual use cases the NN specification would be customized for a particular market, thus yielding even better accuracy and/or higher speed. Either way I think this is a pretty satisfactory result and it can be improved upon further if one allows for more resources.
In terms of calibration then, how does that IV accuracy translate to predicted model parameter accuracy? I will use real-world market data that I had used before to test my PDE-based calibrator; the two SPX option chains from [1] and the DAX chain from [2]. As can be seen in Table 1, the calibration is very accurate and takes a fraction of a second. In practice one would use the last result as the starting point which should help the optimizer converge faster still.
For those who need hard evidence that this actually works as advertised, there's the self-contained console app demo below to download. The options data files for the 3 test chains are included. The calibrator always starts from the same parameter vector (see Table 1) and uses only the CPU to keep things simple and facilitate comparisons with traditional methods. And I have also included a smaller, only slightly less accurate on average NN approximation that is more than double as fast still.
Table 1. Model parameters calibrated to real market data: comparison between NN-based and exact (using Qlib at maximum accuracy settings) calibration . The starting parameter vector is (0.1, 0.1, 5, 2, -0.7).
| SPX Chain A from [1] (246 options) | SPX Chain B from [1] (68 options) | DAX Chain from [2] (102 options) | |||||||||
| Exact | NN | error | Exact | NN | error | Exact | NN | error | |||
| v0 | 0.007316 | 0.007315 | (0.01%) | 0.04575 | 0.04576 | (0.02%) | 0.1964 | 0.1964 | (0.00%) | ||
| v̅ | 0.03608 | 0.03608 | (0.00%) | 0.06862 | 0.06862 | (0.00%) | 0.07441 | 0.07440 | (0.01%) | ||
| k | 6.794 | 6.794 | (0.00%) | 4.906 | 4.903 | (0.06%) | 15.78 | 15.80 | (0.13%) | ||
| x | 2.044 | 2.044 | (0.00%) | 1.526 | 1.525 | (0.07%) | 3.354 | 3.356 | (0.06%) | ||
| r | -0.7184 | -0.7184 | (0.00%) | -0.7128 | -0.7129 | -(0.01%) | -0.5118 | -0.5118 | (0.00%) | ||
| IV RMSE (b.p.) | 128.24 | 128.23 | 0.01 | 101.35 | 101.37 | 0.02 | 131.72 | 131.72 | 0.00 | ||
| CPU time | 0.55 s | 0.16 s | 0.26 s | ||||||||
So to conclude, it is fair to say that the NN (or should I say Machine Learning) approach passed the first real test I threw at it with relative ease. Yes, one needs to invest time to get a feeling of what works and come up with ways to optimize since this is basically an engineering problem. But the results show that at least in this case one can get all the accuracy practically needed in a reasonable amount of (offline) time and resources.
Finally let's briefly mention here the two main perceived issues with this approach: How does one guarantee accuracy everywhere in the input parameter hyperspace (i.e. looking at the tails of the error distribution)? I agree this is an issue but there are ways to increase confidence, especially in relatively simple cases like the one here. The other is lack of transparency and/or interpretability.
COMING UP NEXT: The follow-up post will feature a much more ambitious test: accurate pricing approximation of Barrier Reverse Convertible Autocallables on 4 underlyings. The accuracy demands will be somewhat lower (reflecting the original Monte Carlo pricing), but the training data will be noisy and the dimensionality much higher. I anticipate significant difficulties in guaranteeing an acceptable level of accuracy everywhere given the rapidly changing price function near the barrier for small times to expiry and especially the true temporal discontinuities on the auto-call dates. Can the NN deliver? Stay tuned to find out!
References
[1] Y. Papadopoulos, A. Lewis (2018), “A First Option Calibration of the GARCH Diffusion Model by a PDE Method.”, arXiv:1801.06141v1 [q-fin.CP].
[2] Kangro, R., Parna, K., and Sepp, A., (2004), “Pricing European Style Options under Jump Diffusion Processes with Stochastic Volatility: Applications of Fourier Transform,” Acta et Commentationes Universitatis Tartuensis de Mathematica 8, p. 123-133.
[3] Cui, Y., del Bano Rollin, S., Germano, G. (2017), "Full and fast calibration of the Heston stochastic volatility model", European Journal of Operational Research, 263(2), p. 625–638
[4] Horvath, B., Muguruza, A., Tomas, M. (2019). "Deep learning volatility.", arXiv:1901.09647v2 [q-fin.MF]
[2] Kangro, R., Parna, K., and Sepp, A., (2004), “Pricing European Style Options under Jump Diffusion Processes with Stochastic Volatility: Applications of Fourier Transform,” Acta et Commentationes Universitatis Tartuensis de Mathematica 8, p. 123-133.
[3] Cui, Y., del Bano Rollin, S., Germano, G. (2017), "Full and fast calibration of the Heston stochastic volatility model", European Journal of Operational Research, 263(2), p. 625–638
[4] Horvath, B., Muguruza, A., Tomas, M. (2019). "Deep learning volatility.", arXiv:1901.09647v2 [q-fin.MF]
 RSS Feed
RSS Feed