Pricing discretely monitored barrier options with Monte Carlo comes natural. One just mimics what would really happen, which is to check if the underlying asset crosses the barrier at specific times only. The "simulation" bias is thus zero. In this case pricing can be accurate if our discretization bias is low (preferably using something better than Euler). But things change when the contract specifies continuous monitoring. The simulation cannot mimic the reality of continuous monitoring since we can only use a finite number of time steps for which we can check if the barrier has been crossed. And one would be forgiven to think that using many time steps (such as corresponding to daily monitoring) would be almost equivalent to true continuous monitoring. But this isn't the case. The probability that the asset could have crossed the barrier in between the implemented time steps is still significant and increasing the number of time steps makes the solution converge only slowly towards the continuous limit. Such a naive simulation will therefore always overestimate the value of a continuous barrier option since it ignores the probability that the option knocks out when we are not looking (i.e. in between time steps).
Now there are generally two ways of reducing, or even getting rid of this simulation bias in special cases. The first is to shift the barrier closer to the asset spot in order to compensate for the times when we "blink". The question is by how much should the barrier be shifted? This was first treated by Broadie, Glasserman & Kou [1], for the Black-Scholes model, where they introduced a continuity correction based on the "magical" number 0.5826. Check it out if you haven't. This trick works pretty well when the spot is not very near the barrier and/or when we have many monitoring dates. But in the opposite case, it can be quite bad and produce errors of 5% or more (Gobet, [2]). This gets worse when there is a steep drop of the value near the barrier, as in a down and out put, or an up and out call with low volatility.
The second way is to use an analytic expression for the probability of hitting the barrier between two realized points in a simulated asset path. This is usually referred to as the probabilistic method, or the Brownian bridge technique, since it uses the probability of Brownian motion hitting a point conditional on two fixed end points. As already implied this probability is known analytically (see [2]) for Brownian motion (and consequently for GBM as well). So for the usual GBM asset model (Black-Scholes), this technique can remove the simulation bias completely. One can just use the probability directly, multiplying each path's payoff with the total path survival probability (based on the survival probability of each path segment S[i], S[i+1]). This is preferable when applicable since it results in lower simulation variance. Alternatively one can sample this probability through a uniform variate draw and use it to decide whether the barrier has been crossed or not. This is the only option when we have to perform regression for American exercise. All this is implemented for the Black-Scholes model in the current version of the pricer which you can download here and check this technique in action (see also here). Below is just a simple example.
Now there are generally two ways of reducing, or even getting rid of this simulation bias in special cases. The first is to shift the barrier closer to the asset spot in order to compensate for the times when we "blink". The question is by how much should the barrier be shifted? This was first treated by Broadie, Glasserman & Kou [1], for the Black-Scholes model, where they introduced a continuity correction based on the "magical" number 0.5826. Check it out if you haven't. This trick works pretty well when the spot is not very near the barrier and/or when we have many monitoring dates. But in the opposite case, it can be quite bad and produce errors of 5% or more (Gobet, [2]). This gets worse when there is a steep drop of the value near the barrier, as in a down and out put, or an up and out call with low volatility.
The second way is to use an analytic expression for the probability of hitting the barrier between two realized points in a simulated asset path. This is usually referred to as the probabilistic method, or the Brownian bridge technique, since it uses the probability of Brownian motion hitting a point conditional on two fixed end points. As already implied this probability is known analytically (see [2]) for Brownian motion (and consequently for GBM as well). So for the usual GBM asset model (Black-Scholes), this technique can remove the simulation bias completely. One can just use the probability directly, multiplying each path's payoff with the total path survival probability (based on the survival probability of each path segment S[i], S[i+1]). This is preferable when applicable since it results in lower simulation variance. Alternatively one can sample this probability through a uniform variate draw and use it to decide whether the barrier has been crossed or not. This is the only option when we have to perform regression for American exercise. All this is implemented for the Black-Scholes model in the current version of the pricer which you can download here and check this technique in action (see also here). Below is just a simple example.
As can be seen the probabilistic method (enabled by checking "continuous monitoring") enables exact Monte Carlo pricing of this continuously monitored up and out call (for which of course the exact analytic solution is available and is shown as well and marked by the blue line). By contrast, the barrier-shifting method misprices this option by quite some margin (3.4%), as can be seen in the second slide where the probabilistic correction is unchecked and instead the barrier has been shifted downwards according to BGK's (not so magic here) formula.
Same trick but now with Heston
Now the analytical (Brownian Bridge) hitting probability is only available for a BM/GMB process. But what if we have a not so simple process? Well, as long as the discretization scheme we use for the asset makes it locally BM/GBM (always the case when we use Euler to discretize S, or log(S)), then we can still use this trick. It won't remove the simulation bias completely, but it may do a good job nonetheless. So I thought I'd try it with Heston and see how it performs. I only have two discretization schemes set up, the Full Truncation Euler and the Quadratic Exponential (with Martingale correction). Both are considered short-stepping schemes, though QE-M can do pretty well with long steps as well, especially for vanillas, not so much for path-dependent options. FTE definitely needs short time steps to give acceptable accuracy. Both schemes though use normal increments to march log(S) in time, conditional on the variance process path realization which comes first. So we can still use our BB probability formulas like we did with the Black-Scholes model. The only catch here is that the BB formulas assume constant variance and we have stochastic variance instead (not to mention correlation between the variance and the asset processes). That's why it will only be an approximation. For each asset path segment S[i], S[i+1] we have the corresponding variances v[i] and v[i+1] which we can use in the BB probability formula. Now since we want to see to what extent the simulation (monitoring) bias can be removed, we'd like to get the discretization bias out of the way so that it doesn't cloud the results. For this reason I used the QE-M scheme with daily time steps. The test cases considered are in table 1, all Up and Out calls for 5 different Heston parameter sets, chosen from the literature without too much thought, although I did try to set up case 4 to be a kind of torture test and the Feller condition is violated in case 7. Those two cases are the ones with the largest error as can be seen in table 2. The "exact" price for the continuously monitored options was calculated by the PDE/FDM solver presented in the previous post. The price when the monitoring is discrete (daily) is also shown for comparison. A large number of Sobol-driven paths were used so that the (Q)MC prices shown are converged to all digits shown (last digit may be off by one). As can be seen, it seems that the method yields accurate approximations of the correct continuous price indeed, the highest error being 0.35%. Note also that even with daily monitoring the discrete version prices (plain MC, no correction) are quite different from the continuous ones (up to 37%), showcasing the need for the probabilistic (BB) correction when it's a continuous barrier price we're after.
Now the analytical (Brownian Bridge) hitting probability is only available for a BM/GMB process. But what if we have a not so simple process? Well, as long as the discretization scheme we use for the asset makes it locally BM/GBM (always the case when we use Euler to discretize S, or log(S)), then we can still use this trick. It won't remove the simulation bias completely, but it may do a good job nonetheless. So I thought I'd try it with Heston and see how it performs. I only have two discretization schemes set up, the Full Truncation Euler and the Quadratic Exponential (with Martingale correction). Both are considered short-stepping schemes, though QE-M can do pretty well with long steps as well, especially for vanillas, not so much for path-dependent options. FTE definitely needs short time steps to give acceptable accuracy. Both schemes though use normal increments to march log(S) in time, conditional on the variance process path realization which comes first. So we can still use our BB probability formulas like we did with the Black-Scholes model. The only catch here is that the BB formulas assume constant variance and we have stochastic variance instead (not to mention correlation between the variance and the asset processes). That's why it will only be an approximation. For each asset path segment S[i], S[i+1] we have the corresponding variances v[i] and v[i+1] which we can use in the BB probability formula. Now since we want to see to what extent the simulation (monitoring) bias can be removed, we'd like to get the discretization bias out of the way so that it doesn't cloud the results. For this reason I used the QE-M scheme with daily time steps. The test cases considered are in table 1, all Up and Out calls for 5 different Heston parameter sets, chosen from the literature without too much thought, although I did try to set up case 4 to be a kind of torture test and the Feller condition is violated in case 7. Those two cases are the ones with the largest error as can be seen in table 2. The "exact" price for the continuously monitored options was calculated by the PDE/FDM solver presented in the previous post. The price when the monitoring is discrete (daily) is also shown for comparison. A large number of Sobol-driven paths were used so that the (Q)MC prices shown are converged to all digits shown (last digit may be off by one). As can be seen, it seems that the method yields accurate approximations of the correct continuous price indeed, the highest error being 0.35%. Note also that even with daily monitoring the discrete version prices (plain MC, no correction) are quite different from the continuous ones (up to 37%), showcasing the need for the probabilistic (BB) correction when it's a continuous barrier price we're after.
Table 1. Test cases parameter sets for Up and Out call options.
| κ | η | σ | ρ | rd | rf | T | K | U | So | vo | |
| Case 1 | 5 | 0.16 | 0.9 | 0.1 | 0.1 | 0 | 0.25 | 100 | 120 | 100 | 0.0625 |
| Case 2 | 5 | 0.16 | 0.9 | 0.1 | 0.1 | 0 | 0.25 | 100 | 135 | 130 | 0.0625 |
| Case 3 | 1.5 | 0.04 | 0.3 | -0.9 | 0.025 | 0 | 0.25 | 100 | 115 | 100 | 0.0625 |
| Case 4 | 1.5 | 0.04 | 0.3 | -0.9 | 0.025 | 0 | 0.25 | 100 | 135 | 130 | 0.0625 |
| Case 5 | 3 | 0.12 | 0.04 | 0.6 | 0.01 | 0.04 | 0.25 | 100 | 120 | 100 | 0.09 |
| Case 6 | 2.5 | 0.06 | 0.5 | -0.1 | 0.0507 | 0.0469 | 0.5 | 100 | 120 | 100 | 0.0625 |
| Case 7 | 6.21 | 0.019 | 0.61 | -0.7 | 0.0319 | 0 | 0.5 | 100 | 110 | 100 | 0.010201 |
Table 2. Effectiveness of Monte Carlo with the Probabilistic Continuity Correction for the pricing of cont. monitored barrier options under the Heston model. The MC prices are converged and the time-discretization error is negligible.
| Solver | Price | Difference | |
| Case 1 | PDE/FDM cont. monitoring (exact) | 1.8651 | - |
| MC with 63 timesteps & PCC | 1.8652 | 0.01% | |
| Plain MC with 63 timesteps | 2.1670 | 16% | |
| Case 2 | PDE/FDM cont. monitoring (exact) | 2.5021 | - |
| MC with 63 timesteps & PCC | 2.5032 | 0.04% | |
| Plain MC with 63 timesteps | 3.4159 | 37% | |
| Case 3 | PDE/FDM cont. monitoring (exact) | 2.1312 | - |
| MC with 63 timesteps & PCC | 2.1277 | -0.16% | |
| Plain MC with 63 timesteps | 2.3369 | 10% | |
| Case 4 | PDE/FDM cont. monitoring (exact) | 3.6519 | - |
| MC with 63 timesteps & PCC | 3.6394 | -0.34% | |
| Plain MC with 63 timesteps | 4.6731 | 28% | |
| Case 5 | PDE/FDM cont. monitoring (exact) | 1.6247 | - |
| MC with 63 timesteps & PCC | 1.6249 | 0.01% | |
| Plain MC with 63 timesteps | 1.8890 | 16% | |
| Case 6 | PDE/FDM cont. monitoring (exact) | 1.7444 | - |
| MC with 125 timesteps & PCC | 1.7438 | -0.03% | |
| Plain MC with 125 timesteps | 1.9209 | 10.1% | |
| Case 7 | PDE/FDM cont. monitoring (exact) | 1.9856 | - |
| MC with 125 timesteps & PCC | 1.9790 | -0.33% | |
| Plain MC with 125 timesteps | 2.0839 | 4.95% |
Finally regarding the variance value used in the probability formulas, my brief testing showed that the best results were obtained when using the variance corresponding to the one of the two nodes S[i] and S[i+1] which is closer to the barrier. This was the choice for the results of Table 2.
Once I set up a more accurate long stepping discretization scheme, I may test to see how well this approximation holds when one uses fewer/longer time steps.
Once I set up a more accurate long stepping discretization scheme, I may test to see how well this approximation holds when one uses fewer/longer time steps.
References
[1] Broadie M, Glasserman P, & Kou S. A continuity correction for discrete barrier options, Mathematical Finance, Vol. 7 (4) (1997), pp. 325-348.
[2] Emmanuel Gobet. Advanced Monte Carlo methods for barrier and related exotic options. Bensoussan A., Zhang Q. et Ciarlet P. Mathematical Modeling and Numerical Methods in Finance, Elsevier, pp.497-528, 2009, Handbook of Numerical Analysis
[2] Emmanuel Gobet. Advanced Monte Carlo methods for barrier and related exotic options. Bensoussan A., Zhang Q. et Ciarlet P. Mathematical Modeling and Numerical Methods in Finance, Elsevier, pp.497-528, 2009, Handbook of Numerical Analysis
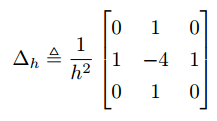
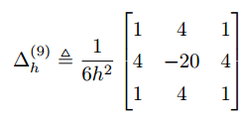
 RSS Feed
RSS Feed